Kademlia (DHT) is a distributed hash table for decentralized peer-to-peer computer networks designed by Petar Maymounkov and David Mazières in 2002. It specifies the structure of the network and the exchange of information through node lookups. Kademlia nodes communicate among themselves using UDP. A virtual or overlay network is formed by the participant nodes. Each node is identified by a number or node ID. The node ID serves not only as identification, but the Kademlia algorithm uses the node ID to locate values (usually file hashes or keywords). In fact, the node ID provides a direct map to file hashes and that node stores information on where to obtain the file or resource.
When searching for some value, the algorithm needs to know the associated key and explores the network in several steps. Each step will find nodes that are closer to the key until the contacted node returns the value or no more closer nodes are found. This is very efficient: Like many other DHTs, Kademlia contacts only nodes during the search out of a total of nodes in the system.
Further advantages are found particularly in the decentralized structure, which increases the resistance against a denial-of-service attack (DDoS). Even if a whole set of nodes is flooded, this will have limited effect on network availability, since the network will recover itself by knitting the network around these "holes".
Following are some details of Kadmealia DHT which will help you understand the concept better.
Every peer/node in Ethereum network has an Id (64 byte wide) which is nothing but a public key derived form a random 256 bit number. Kadmelia normally has 160 bit wide NodeId but for Ethereum network it is 64 byte wide which is width of public key.
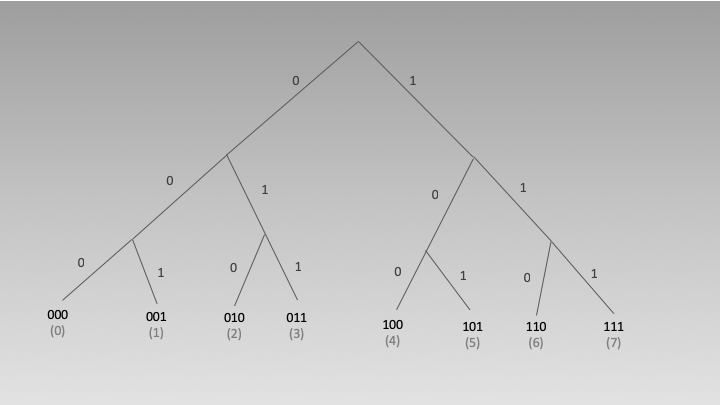
Every node/peer maintains an instance of Kadmealia DHT which is implemented in form of a binary tree. Peers are stored at leaves. There is notion of distance of one peer from another which is represented as x^y(x XOR Y) where "x" and "y" are Node Ids of the two different peers.
To make it more clear, lets consider the following tree which stores peers with 3 bit wide NodeId.
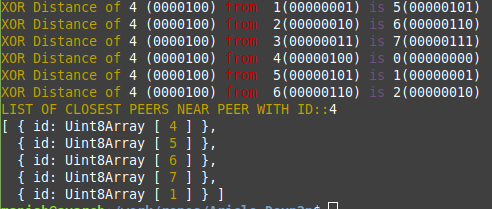
Now lets say another peer with node id 100(4) ask this node to return 5 closest peer, as per below XOR table it will return peers with Id 4,5,6,7 and 1
Decimal
Binary
XOR distance
4^0
100^000
4
4^1
100^001
5
4^2
100^010
6
4^3
100^011
7
4^4
100^100
0
4^5
100^101
1
4^6
100^110
2
4^7
100^111
3
By design it will store more numbers of peers close to own NodeId address space, which is very beautifully explained here, (page number 71-105).
Here is GitHub link, I've checked-in simple code to see things in action. It's creating a node of one byte id with Node Id "00000000" then adding 7 peers with Ids ranging from 1 to 7 to simulate 7 Ethereum network peers and then look for nearest peers respect to peer 4.
const node = new KBucket({
localNodeId: Buffer.alloc(1,0)
})
And add seven peers..
const peer1 = new Uint8Array([1])
const peer2 = new Uint8Array([2])
const peer3 = new Uint8Array([3])
const peer4 = new Uint8Array([4])
const peer5 = new Uint8Array([5])
const peer6 = new Uint8Array([6])
const peer7 = new Uint8Array([7])
// Add all the peers to KDT
node.add({"id":peer1})
node.add({"id":peer2})
node.add({"id":peer3})
node.add({"id":peer4})
node.add({"id":peer5})
node.add({"id":peer6})
node.add({"id":peer7})
Distributed Hash Tables are a form of a distributed database that can store and retrieve information associated with a key in a network of peer nodes that can join and leave the network at any time. The nodes coordinate among themselves to balance and store data in the network without any central coordinating party. Distributed Hash Tables are both fault tolerant and resilient when key/value pairs are replicated. The ability to distribute data among the peers is in strong contrast to the Blockchain model in which every node has a copy of the entire ledger. This is a critical distinction and could allow for the ability to move health records out of the silos of the EHR systems.
Distributed Hash Table Overview
Structure of keys
DHT’s require that information to be evenly distributed across the network. To achieve this goal, the concept of consistent hashing is used. A key is passed through a hash algorithm that serves as a randomization function. This ensures that each node in the network has an equal chance of being chosen to store the key/value pair.
Routing and Lookup Cost
Because DHT nodes don’t store all the data, there needs to be a routing layer so that any node can locate the node that stores a particular key. The mechanics of how the routing table works, and how the table is updated as nodes join and leave the network is a key differentiator between different DHT algorithms. In general, DHT nodes will only store a portion of the routing information in the network. This means that when a node joins the network, routing information only needs to be disseminated to a small number of peers.
Because each node only contains a portion of the routing table, the process of finding or storing a key/value pair requires contacting multiple nodes. The number of nodes that needs to be contacted is related to the amount of routing information each node stores. Common lookup complexity is O(log n) where n is the number of nodes in the network. For example, in a network of a million nodes, only 20 nodes would need to be found. Some DHT algorithms allow for a tradeoff of increasing the amount of router state to further reduce the worst case lookup cost. Route tables are relatively small, and a production DHT operating over a WAN would likely choose to increase the routing table size and could likely further reduce the worst case lookup by half or more.
Iterative and Recursive Lookup
There are two common styles of lookup operations. In an iterative lookup, a requesting node will query another node asking for a key/value pair. If that node does not have that node, it will return one or more nodes that are “closer”. The requesting node will then query the next closest node. This process repeats until either the key/value is found and returned, or the last queried node returns an error saying that the key simply cannot be found.
With recursive lookups, the first requesting node will query the next closes node, which will then query the next closest node until the data is found. The data is then passed back along the chain of requests back to the requestor.
Example Routing Table
In Figure 3 we see a worked example. The example is not representative of any particular DHT algorithm and is intended to illustrate the general concepts of how DHT’s work. Node ID’s and keys must be random numbers are typically the output of a hashing algorithm. Each node is assigned a portion of the keyspace and maintains portion of routing table. The details of how the routing table is maintained as nodes join and leave the network, and how replication is implemented are key differentiators between different DHT algorithms.
DHT’s are not like traditional hash tables in computer science that of a lookup complexity of O(1) — or only one memory address needs to be accessed in order to find the associated value. Each DHT node only contains a portion of the key/value pairs, and only a portion of the
Healthcare Example
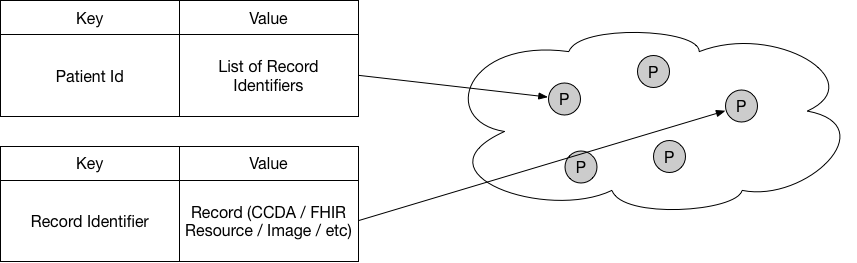
DHT’s — like all distributed databases — are good at key/value lookups, but are not good with joins. In the context of a DHT, a join is when multiple key/values need to be looked up to retrieve the information needed. For example, the entire patient record could be stored as a single key/value pair. This reduces the lookup time, for a single record, but if the patient record is sizeable, it would take a lot of network bandwidth and time to download the entire file. Compromises can be made and in the example below, there is a key that stores a list of keys to other documents. It acts like a search index for a patient’s record. The record is broken up and each component is stored under its own key/value pair. This approach allows a requestor to only download the records they want and more evenly distributes the data across the network and thus increases data durability and availability.
Comparing security in Blockchains and DHT’s
Blockchain nodes need to store the entire database in order to maintain their security guarantees. This means that it is simply not practical to store the patient’s record directly on a Blockchain because the amount of data in all the patients in the United States would mean that each Blockchain node would need to store a HUGE amount of data. This would be cost prohibitive. Additionally, even if the Blockchain is optimized to store only small and compressed amounts of patient data, the security risks would be massive. The compromise of even a single Blockchain node would be a massive data breach on the scale of the Equifax breach. The liability would be massive. In general, the only safe way to store private information in a Blockchain is to encrypt the data. However, with encrypted data, you also limit the overall usefulness of storing information in a Blockchain. For example, if data was encrypted, it is not clear how a common use case such as access to patient records in an emergency would be implemented.
These limitations are commonly understood in the Blockchain community, and as such the use of Blockchain is more realistically being limited to storing hashes and locations of patient’s records stored elsewhere. This reduces the risk of data disclosure, but in doing so, reduces the value proposition of the Blockchain for healthcare which is about everyone having access to data. To recap, if you store patient records on a Blockchain, you run into both scalability problems and create a security nightmare. If you only store hashes and pointers, the Blockchain doesn’t offer anything more than existing non-blockchain systems such as CareQuality and CommonWell.
Blockchain Vs CareQuality and CommonWell
In order to achieve healthcare data exchange, you some or all of the following:
- A provider registry
- A master patient index or single patient identifier
- API (FHIR / XDS.b / HL7 / etc) and data (ICD / SNOMED / etc) standards
- A patient search index
- A service registry
- Trust Framework
o Common security standards (SAML / X.509 / PKI / OAuth, etc)
o Identity management for network members (certificate registry)
o Legal agreements and terms of use
These elements are commonly provided via a consortium such as CareQuality and CommonWell as well as some HIEs. These consortiums currently provide the necessary ingredients to exchange data in a scalable manner without the use of Blockchain. For healthcare exchange, a Blockchain network would need a governing consortium and it’s not clear that a consortium would benefit from the use of Blockchain when it can use traditional software approaches at a lower cost. The great touted use of Blockchain as a means of providing strong integrity guarantees can be easily implemented by a consortium by no means requires the use of a Blockchain.
The records themselves would still be stored at source EHR databases. While this is a feasible use of a Blockchain, it provides limited value. The Blockchain search index may be highly available and durable, but that does not extend to the patients data as the data itself is stored in the EHR databases that may not maintain the data over time and the API’s to access may themselves not be highly available.
Key Innovations of a DHT Based Healthcare Record System
A DHT operated by a consortium would offer a number of advantages that would revolutionize healthcare data exchange. In a DHT based system, data can be moved out of the EHR silos and into a database that is centrally governed by the consortium. Data is now highly available and durable and can even survive when a doctor goes out of business or loses patient data. In effect, it is possible to have a true cradle to grave patient record. Because all DHT nodes share common software, which would be managed by the consortium, the consortium would provide a single point of access for other stakeholders that need access to data such as researchers, disease registries, third party vendors,, and more. The central governance of the network would allow the network to have monetary value which can be capture and passed on to the healthcare providers. This would replace the need for meaningful use grants and provide a sustainable source of funding for continuing maintenance and advances of EHR systems.
Additional Cost Advantages
A common difficulty with interoperability is the delay in getting agreements to define, use, and most importantly, implement a standard. In a large enterprise, there are hundreds of individual companies that need to update their software and even more users that need to pay for and install upgrades that implement those standards. The wide number of individual parties means that innovation proceeds at a very expensive crawl. In comparison, in a DHT managed consortium, the database software and management is controlled by a single entity. This dramatically reduces the cost and greatly increases the pace of innovation and change.

 nodes during the search out of a total of
nodes during the search out of a total of  nodes in the system.
nodes in the system.